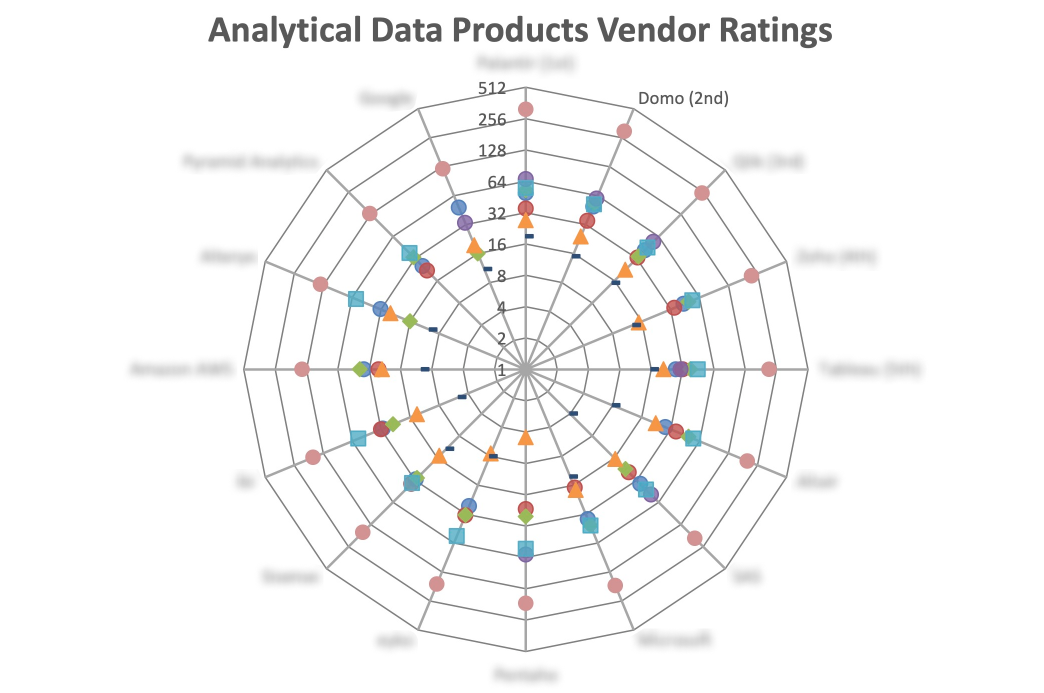
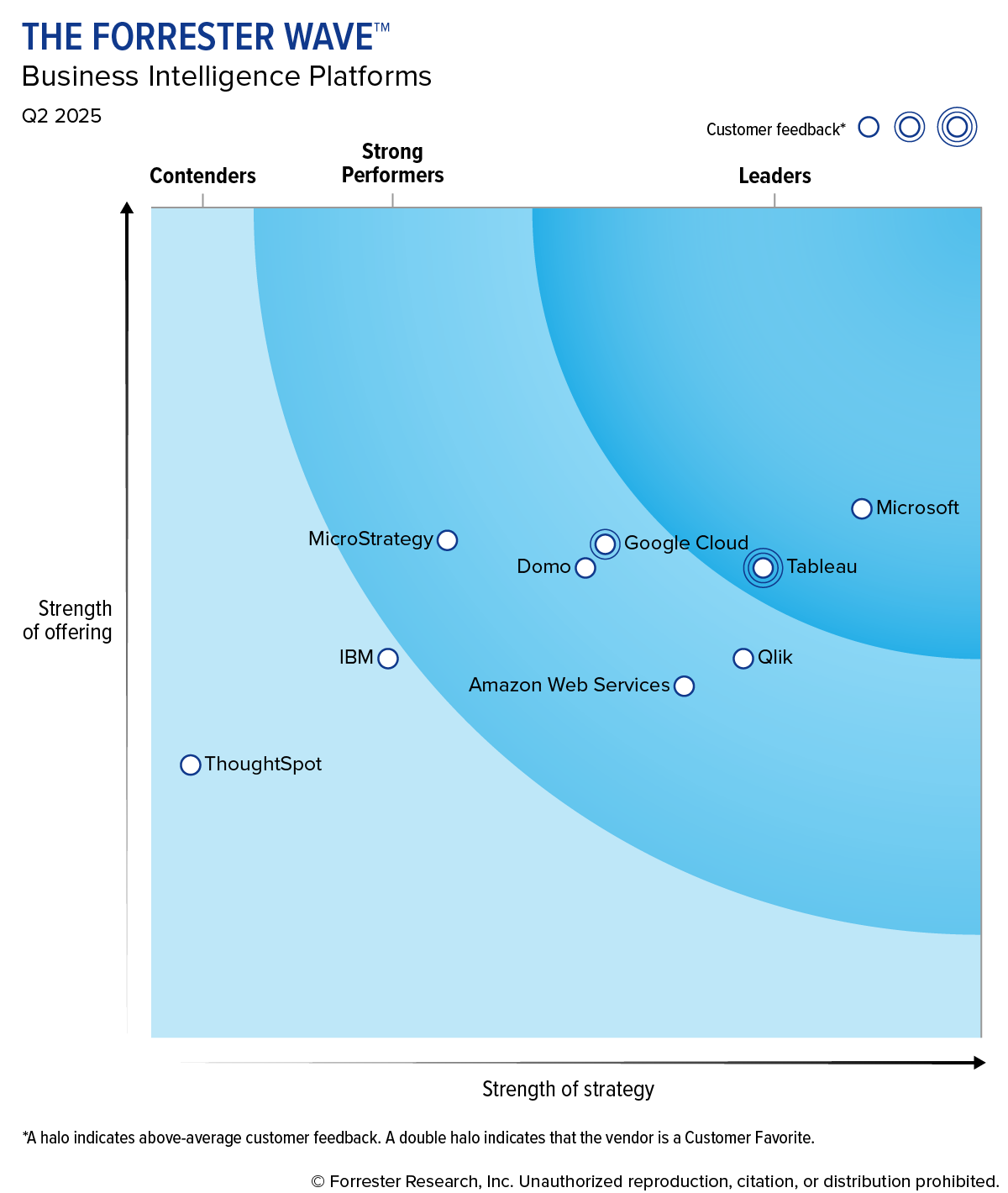
Saved 100s of hours of manual processes when predicting game viewership when using Domo’s automated dataflow engine.
Resource Center
Use Domo to empower your teams with cutting-edge AI solutions designed for security, scalability, and trust. Reimagine what’s possible with your data.
Explore content types





.png)































































































































.png)
































































































































































































.avif)